
The word “metadata” may have entered the public consciousness when President Obama uttered it, in response to Edward Snowden’s revelations about the National Security Agency. But that does not mean it’s vernacular—or necessarily well understood by most people.
Metadata has implications beyond privacy. In education, where technology offers the potential to “personalize” the learning experience for students, metadata is critical. Not only are technologists and entrepreneurs saying this; the federal government, as part of its #GoOpen campaign, has acknowledged the value of metadata for its ability to make high-quality, openly-licensed educational resources more easily discoverable.
But what does “metadata” mean, and how do tools leverage it to create personalized learning experiences?
Metadata vs Data
At a high level, metadata is simply data that helps describe other data. Today, metadata is electronic, but historically, it was contained in a library card catalog. Metadata consists of tags generated by some combination of computers and humans.
On most webpages, metadata consists of tags that help other websites and applications understand what it is about. For example, here is an example from Yelp of my favorite taqueria, Los Dos Amigos. A website that simply lists the address without any metadata might say, “the restaurant is in San Mateo over on B Street.” To make the restaurant more easier to be found and read by machines and people, Yelp translates that data into metadata for location: “San Mateo” and “Downtown.”
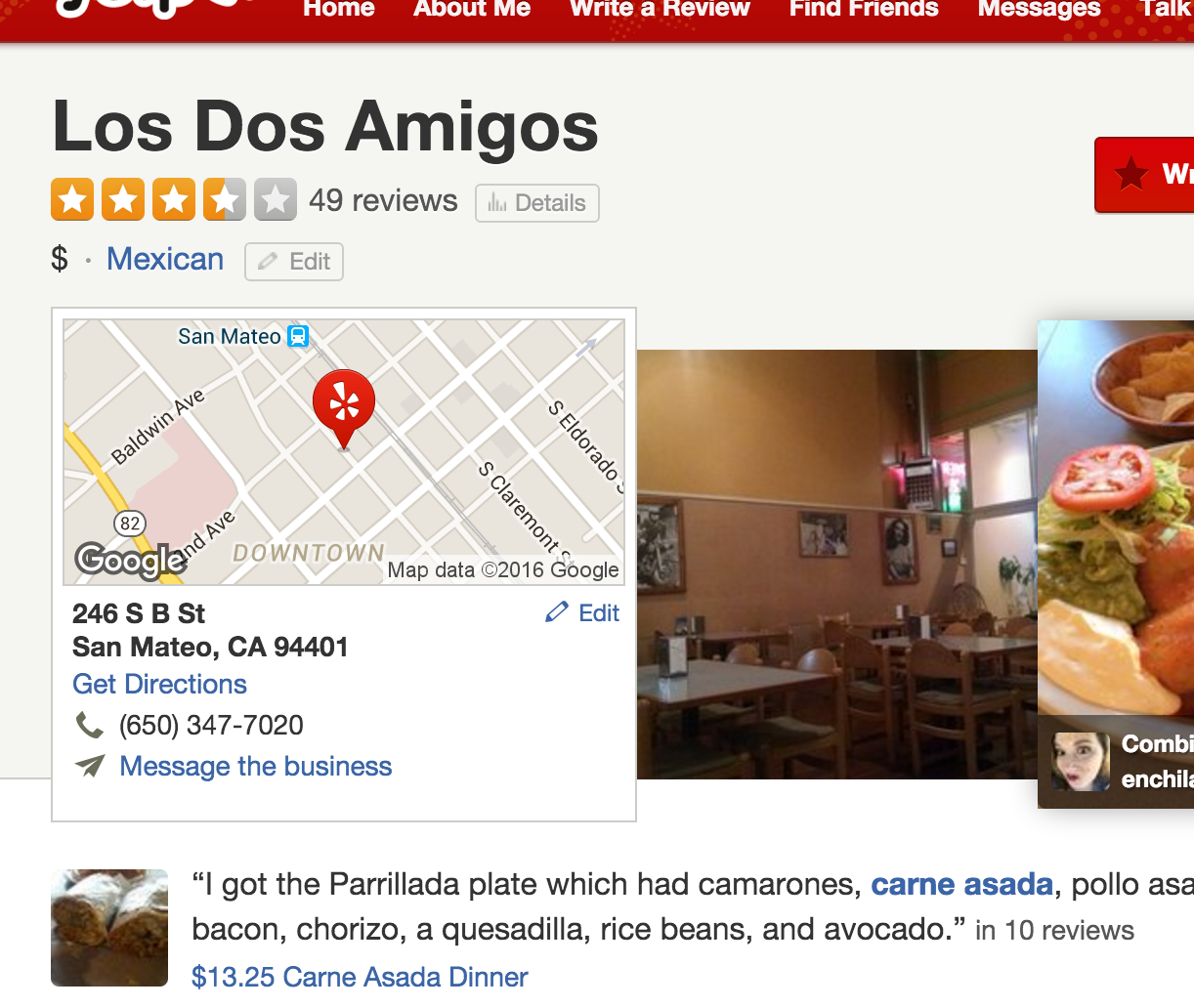
Yelp also collects and organizes other metadata including city, type of cuisine and cost. There is also a combination of user-generated content (such as the Yelp user ratings) and machine-generated content (the city name is clearly taken from Google Maps.)
Here’s what metadata looks like in the educational hip hop videos produced by Flocabulary.

Flocabulary publishes metadata for topics, grades, Common Core alignment and other information the company believes to be relevant for users. (As an example, for any time a human or a computer is looking for CCSS Literacy RL.4.3, Flocabulary’s metadata is showing exactly which videos are aligned to that standard.) In the future, it could also add metadata on effectiveness and user ratings.
The more comprehensive the metadata on a resource, the easier it is for other tools and services to find it, provided they have access. Teachers, too, can also quickly find resources that best fit the different learning styles, needs and levels of each student. Therefore, metadata offers enormous potential for online learning resources to be accessible through personalized learning platforms emerging today.
Metadata’s Meta-Problems
But metadata also poses problems, namely: Who is responsible for creating and maintaining it? Hiring experts is expensive, volunteer experts are typically too busy to go through and classify. But if tagging is open to anyone, it opens the door for inaccurate data. Furthermore, tags can quickly become outdated; metadata added to educational resources a couple of years ago would need to be updated for many of the new state standards that have emerged in states like Indiana, Georgia and Florida. An additional problem is the instructions on how to add metadata to websites on www.schema.org by definition contain HTML, which is not the normal language among curriclum specialists.
As an example of what human-generated tags cannot do, it is highly unlikely users of an online learning resource will be able to consistently add accurate tags for standard alignment, or the different kinds of accessibility needs for special-ed learners. However, there are types of metadata that lend themselves well to classification by crowdsourcing, such as if advertisements are acceptable or not.
Some publishers and companies have turned to crowdsourcing metadata—essentially asking teachers to “add tags.” One example is OER Commons.

Amazon is considering this approach with Amazon Inspire, a repository that allows teachers to upload, manage, share, and discover resources in a way that resembles Amazon’s reviewing and purchasing systems. The platform will make the content searchable by assigning metadata tags organized by the Learning Registry, a federal effort to aggregate data around how digital resources are created and used.
Metadata is best created automatically. As an example, if a resource is already tagged by an academic standard, it is simple for a machine to create additional metadata for the appropriate grade level (without requiring people to do so). For visual resources, machines can also detect if an image is of a size and resolution that is suitable for printing.
Getting the basic level of metadata in education should be the priority, especially as many open educational resources exist in silos. Increasingly, platforms such as those offered by Amazon and Edmodo are encouraging teachers to publish their own resources to the web. Metadata can help organize this growing cache of valuable content. After all, teachers typically prefer not to have to watch or access every resource in order to figure out whether it is appropriate.
There are two ways to get better metadata on educational resources and therefore, move the needle on personalized education.
- Publishers can add their own metadata. The more technical publishers are already doing so to varying degrees, but the ones I have spoken to have confusion on both what to add and how to do it.
- Catalogs (that aggregate content many publishers) can add metadata to resources for the publishers using automated or manual methods, as is being done by the US Government’s Learning Registry, OpenEd.com (where I work), and several state repositories. Edtech tools can then access the resources from a catalog rather than going to each publisher.
The largest current gap is a way for publishers to understand how to add their own metadata via the educational attributes in schema.org, and of course find time to do so. There is room in the marketplace for software or consulting help to assist publishers in publishing the correct metadata.


{kind=link}